Reverse ETL for Analytics Activation
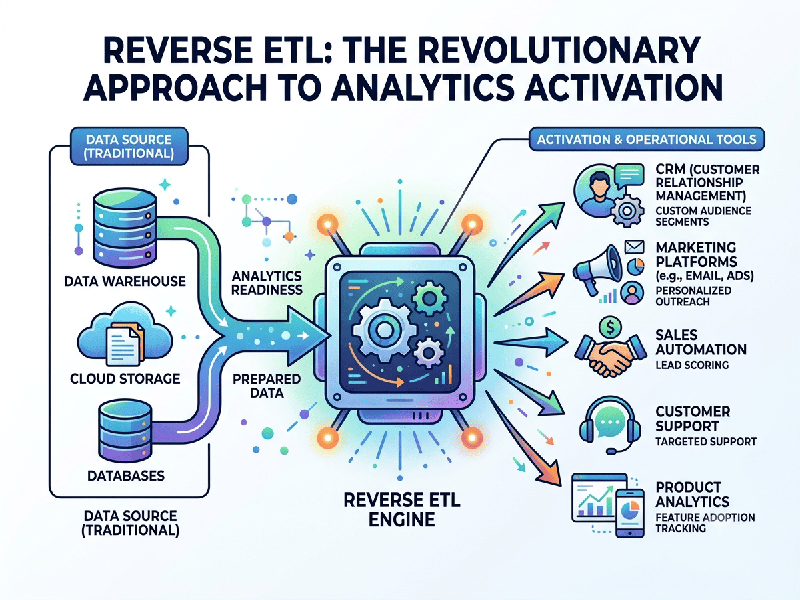
Reverse ETL (Extract, Transform, Load) is a data integration process that
moves data from a centralized data warehouse or data lake back into the
operational tools (SaaS applications) that business teams use every day, such
as Salesforce, HubSpot, Zendesk, or Slack.
While traditional ETL moves data into a
warehouse for analysis, Reverse ETL "activates" that data by making
it actionable for marketing, sales, and customer support teams.
How Reverse ETL Works
In a standard data stack, data is gathered in a
warehouse, analyzed by data scientists, and left as "insight trapped in a
dashboard." Reverse ETL closes this loop:
1.
Sync: The
Reverse ETL tool connects to your data warehouse (e.g., Snowflake, BigQuery,
Redshift).
2.
Select & Map: You select the data (e.g., "Predicted Customer Lifetime
Value") and map it to a specific field in an operational tool (e.g.,
"Customer Score" field in Salesforce).
3.
Schedule: The
tool automatically syncs the data on a set schedule or in real-time, ensuring
operational teams always have fresh data.
Why Businesses Use Reverse ETL
Before Reverse ETL, operational teams often worked
with "stale" or incomplete data, or had to manually export/import
CSVs. Reverse ETL solves this by:
- Operationalizing Insights: Instead of asking sales reps to
check a BI dashboard for account health, the health score is pushed
directly into their CRM.
- Single Source of Truth: By performing transformations
in the warehouse (using tools like dbt) before syncing back to apps, you
ensure that every team is using the same calculated metrics.
- Reduced Engineering Burden: It eliminates the need for
engineers to build custom APIs and point-to-point integrations for every
single SaaS tool the company uses.
Key Capabilities to Look For
If you are evaluating Reverse ETL tools (like Census,
Hightouch, or Grouparoo), look for these features:
- Bidirectional Sync: The ability to not just push
data, but also monitor for conflicts.
- Alerting & Monitoring: Real-time notifications when a
sync fails or data validation rules are triggered (essential for keeping
data reliable).
- Version Control: Integration with Git (via dbt)
so that your data transformations are tracked and audited.
Privacy & Governance: Built-in controls to ensure PII (Personally Identifiable Information) isn't accidentally pushed to tools that shouldn't have access to it.