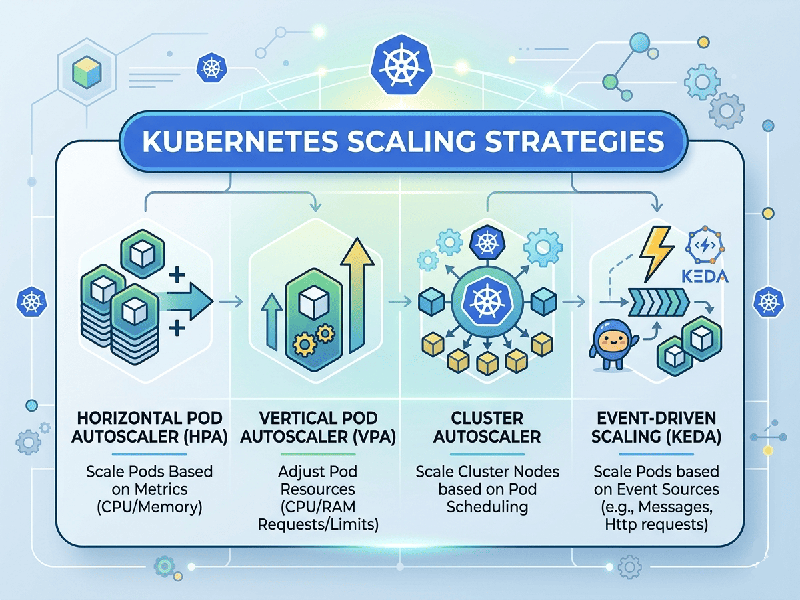
Kubernetes Scaling Strategies
To maintain high availability and keep cloud costs under
control, Kubernetes scales across two primary layers: Workload Scaling
(Pods) and Infrastructure Scaling (Nodes).
Relying on just one layer leaves your system vulnerable to
either wasted cloud spend or application downtime. Effective orchestration
requires a multi-layered autoscaling approach.
1. Horizontal Pod Autoscaler (HPA)
- What it does: Adjusts the number of pod
replicas (scales out/in) inside a Deployment or StatefulSet.
- How it triggers: Monitors metrics (typically CPU
and memory utilization) via the Metrics Server. If the average utilization
passes your target threshold (e.g., 60%), it spins up more pods.
- Best For: Stateless microservices, REST
APIs, and event-driven workloads experiencing unpredictable traffic
spikes.
2. Vertical Pod Autoscaler (VPA)
- What it does: Adjusts the exact CPU and
memory requests and limits (scales up/down) of individual containers
rather than adding more pods.
- How it triggers: The VPA Recommender
tracks actual resource consumption over time and right-sizes the pod to
prevent application throttling or idling.
- Best For: Stateful applications (like
databases), batch jobs, or workloads with steady traffic but highly
unpredictable baseline resource usage.
3. Cluster Autoscaler (CA)
- What it does: Adjusts the physical
infrastructure layer by adding or removing worker nodes (VMs/EC2
instances) from your cloud provider node pools.
- How it triggers: It triggers only when a pod
is marked as Pending because the existing nodes lack the unallocated
CPU or memory to schedule it. Conversely, it gracefully drains and
terminates nodes if they are underutilized.
2026 Advanced & Event-Driven Scaling Strategies
Standard metrics like CPU and memory are lagging
indicators—they spike after performance degrades. Advanced cloud-native
architectures implement proactive and event-driven scaling:
KEDA (Kubernetes Event-driven Autoscaling)
Instead of waiting for a container to get hot, KEDA
integrates directly with HPA to scale workloads based on actual external
events.
- Kafka / RabbitMQ: Scale pods based on queue
length or lag.
- Prometheus / Cloud Metrics: Scale based on HTTP request
rates, active WebSocket connections, or business logic.
- Cron-based: Scale out ahead of known peak
hours (e.g., right before a flash sale) and scale in overnight.
Rapid Infrastructure Provisioning (Karpenter)
While traditional Cluster Autoscalers are tied to uniform
node groups, modern alternatives like AWS Karpenter evaluate the concrete
resource requirements of pending pods and launch the optimal machine type
(evaluating compute, pricing, and availability zone) directly from the EC2
fleet in seconds.