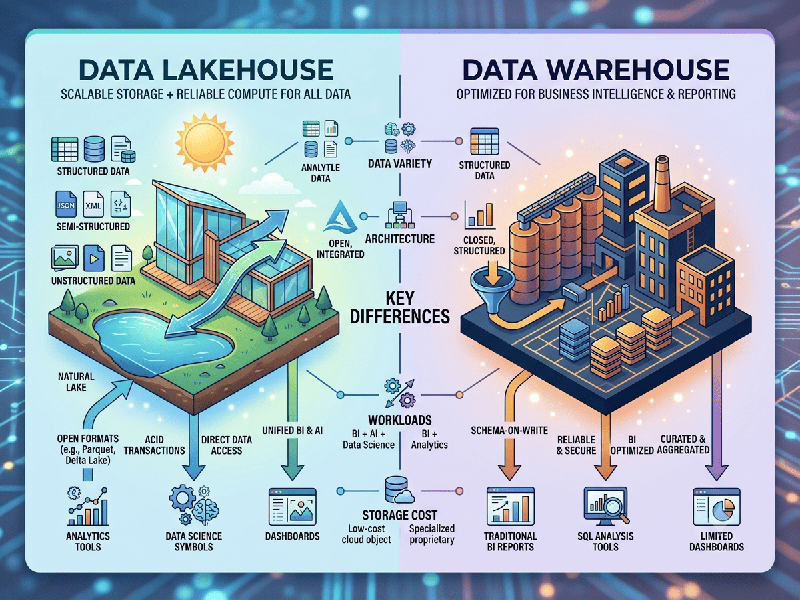
Data Lakehouse vs Data Warehouse
To understand the evolution of modern data architecture, it
is best to view a Data Warehouse and a Data Lakehouse as
solutions for different types of data needs.
Data Warehouse
A Data Warehouse is a structured, optimized repository
designed primarily for Business Intelligence (BI) and reporting.
- Data Structure: Primarily stores highly
structured, processed data (schema-on-write).
- Purpose: Best for historical analysis,
executive reporting, and complex SQL queries where performance and
consistency are critical.
- Technology: Relies on high-performance
relational databases.
- Limitation: It is expensive to scale and
struggles to handle unstructured data (like video, social media logs, or
images) or real-time streaming data.
Data Lakehouse
A Data Lakehouse is a hybrid architecture that
combines the cost-effectiveness and flexibility of a Data Lake with the
performance, reliability, and management features of a Data Warehouse.
- Data Structure: Supports both structured and
semi-structured/unstructured data. It applies a "schema-on-read"
approach, allowing for greater agility.
- Purpose: Designed for both traditional
BI reporting and modern Machine Learning (ML) or Data Science
workloads.
- Technology: Built on low-cost object
storage (like S3 or Azure Data Lake Storage) but uses an open-table format
(e.g., Delta Lake, Iceberg, or Hudi) to provide ACID transactions and
metadata layers that mimic a warehouse.
- Advantage: Eliminates the "data
silos" that occur when you keep a separate Data Lake and Data
Warehouse.