AI Model Monitoring
AI Model Monitoring is the continuous process of tracking a
machine learning model's performance, health, and reliability after it has been
deployed into production. Think of it as a "check engine light" for
your AI—ensuring that the model, which performed perfectly in the lab, doesn't
fail when it meets the messy, ever-changing real world.
1. Why is Monitoring Necessary?
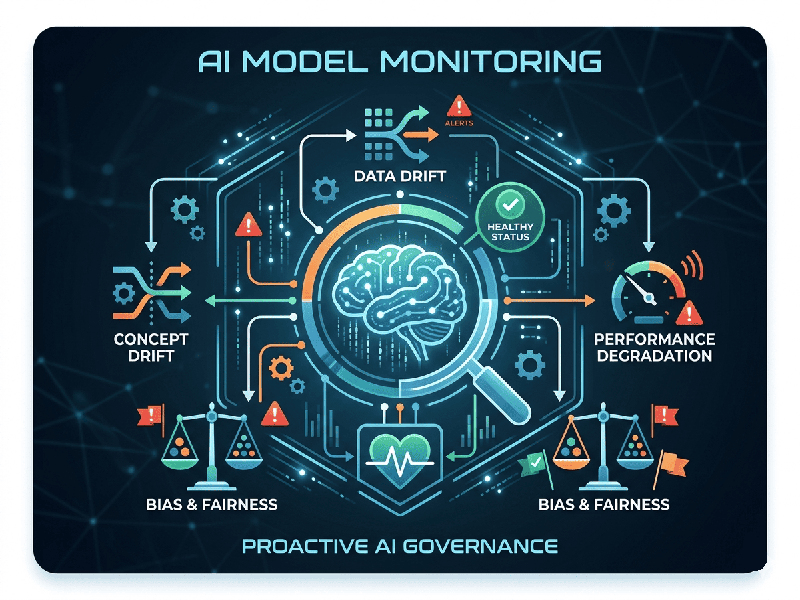
Unlike traditional software, AI models are probabilistic.
Even if your code doesn't change, your model's accuracy can decay over time
because the world around it changes. This is generally referred to as Model
Drift.
- Data Drift: The input data changes (e.g., a
model trained on desktop users suddenly receives mostly mobile traffic).
- Concept Drift: The "rules" of the
world change (e.g., a fraud detection model becomes outdated because
scammers have invented new, sophisticated methods).
2. Specialized Metrics for 2026
In the era of Generative AI and LLMs, monitoring has moved
beyond simple accuracy scores:
- Hallucination Detection: Measuring how often the model
generates factually incorrect or nonsensical information.
- Toxicity & Bias: Ensuring the model isn't
outputting harmful, biased, or restricted content.
- Context Retention: For AI agents, tracking how
well they remember previous parts of a conversation.
- Tool-Use Accuracy: For "Agentic" AI,
monitoring if the model calls the correct external API or tool at the
right time.
3. Modern Tooling Landscape
If you are looking to implement monitoring, these are the
current industry leaders (as of 2026):
- Levo.ai / Arize AI: Top-tier platforms for tracking
model drift and agent behavior in real-time.
- Fiddler AI: Specialized in Explainability
(answering why a model made a certain decision) and bias detection.
- Datadog / New Relic: Great for
"full-stack" observability, linking model performance to your
server's health.
- LangSmith: The gold standard for
developers debugging and tracing LLM chains.
4. The Monitoring Workflow
1.
Establish a Baseline: Record the model's performance on the original training data.
2.
Set Thresholds:
Define "Alert" zones (e.g., "Alert me if accuracy drops below
85%").
3.
Automate Alerts: Use tools to notify engineers via Slack or PagerDuty when drift is
detected.
4.
Retrain & Redeploy: Once a model decays, use the newly collected production data
to retrain it, closing the loop.