Cloud DR Patterns
Cloud Disaster Recovery (DR) patterns are strategies used to ensure that your applications and data remain available if your primary cloud region or dat4 a center fails. The choice of pattern usually depends on your RTO (Recovery Time Objective—how fast you need to be back up) and RPO (Recovery Point Objective—how much data you can afford to lose).
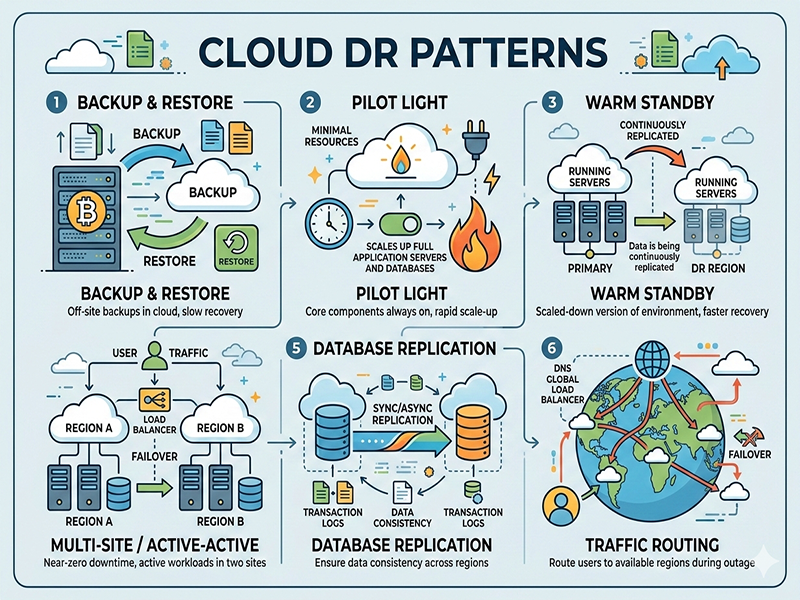
1. Backup
and Restore (Cold Standby)
This is the
simplest and most cost-effective pattern. You regularly back up your data and
applications to a different cloud region. In the event of a disaster, you must
"rebuild" the entire environment from those backups.
- RTO: Hours to days (you have to
provision servers and restore data).
- RPO: 24 hours (or whenever your last
backup occurred).
- Best for: Non-critical internal systems
or small businesses.
2. Pilot
Light (Core Data Only)
In a Pilot
Light pattern, your data is continuously replicated to the DR region, but your
application servers are kept "off" or in a dormant state (like an
Amazon Machine Image or a container image). Only the "pilot
light"—the database—is kept burning.
- RTO: 10s of minutes to an hour (you
must "ignite" or scale up the app servers).
- RPO: Minutes (based on data
replication lag).
- Best for: Most standard business
applications where an hour of downtime is acceptable.
3. Warm
Standby (Scaled-Down Version)
This is a
"mini-me" version of your production environment. A scaled-down
version of your full stack is always running in the DR region. When a disaster
strikes, you simply scale up the existing instances to handle the full
production load.
- RTO: Minutes (nearly instantaneous,
just needs a DNS flip and auto-scaling).
- RPO: Seconds to minutes.
- Best for: Critical customer-facing
applications.
4.
Multi-Site Active-Active (Hot Standby)
In this
pattern, your application is running in two or more regions simultaneously.
Traffic is distributed between them using a global load balancer (like AWS
Route 53 or Cloudflare). If one region goes down, the other simply continues to
handle the traffic.
- RTO: Zero (the system is already
running).
- RPO: Zero (assuming synchronous data
replication).
- Best for: Mission-critical systems
(Banking, Healthcare, Global SaaS).